随着深度神经网络的发展,深度学习在文本生成比如nueral machine translation(NMT)以及question answer(QA)等任务中突破了传统方法的瓶颈,在很多数据集上都取得了state-of-the-art(SOTA)的效果。
我们知道神经网络输入层必须接收数字形式的信息,所以必须将文本形式的词嵌入成向量。通常会设定一个词汇表大小,对于词汇表中所有词有对应的向量表示。而由于一种语言涵盖的词汇太多,以及处理的文本数据本身就不规范(比如web数据),从而无法覆盖所有的词汇,在对corpus中的词进行向量map时会出现out of vocabulary(OOV)的现象。以往的做法是设置一个特殊字段(比如UNK)来表示所有OOV的词汇,这种做法可谓相当粗糙,那有没有更细致微妙的处理方法呢?答案当然是有的,很多从事NLP研究的工作者在这个方面开展了不少的工作。一种方法是从word embedding扩展到character embedding,另外一种方法是将word拆分成有意义的更小的词素也就是wordpieces,两个word可能不相同,但是他们可能包含相同的wordpieces,这样对于OOV的word,找到其对应的wordpieces的向量added or averaged也可以蕴含该word的word sense。接下来分别介绍这两种方法。
Character Embedding
在没出现character embedding之前可能会觉得仅用少量的字符向量就可以表示含有丰富含义的词向量会有点不可思议,但借助于神经网络对特征强大的组合能力,使得这一切成为了可能。目前对word中的characters进行组合的方式目前主要有convolutional network和LSTM network两种。下面分别介绍这两种方法以及混合使用word-character embedding的模型。
Convolutional
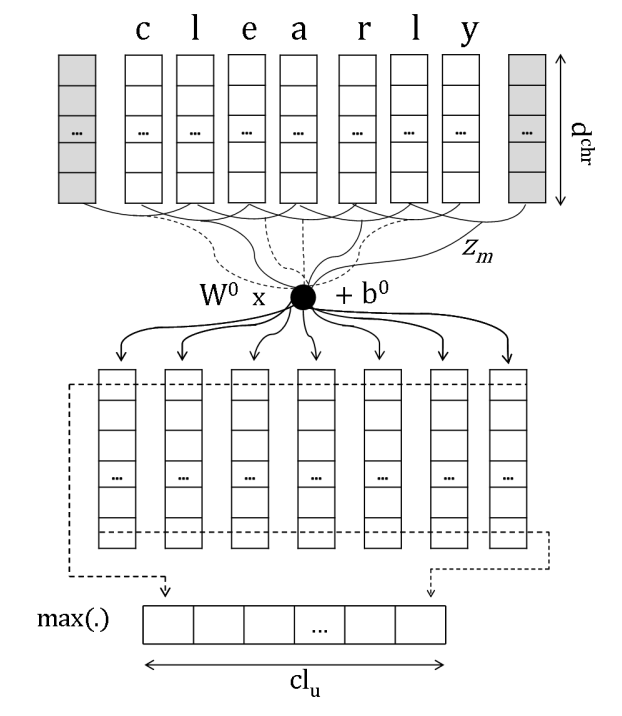
Learning Character-level Representations for Part-of-Speech Tagging C´ıcero,这篇文章发表于JMLR2014,应该是最早的使用卷积神经网络处理char embedding的,模型主要分三层conv+fcn+maxpool,具体的结构图如下
LSTM
Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation,这篇文章发表于EMNLP2015,使用LSTM网络处理char embedding,并将其很好得应用于language model和POS tagging,具体的模型结构如下
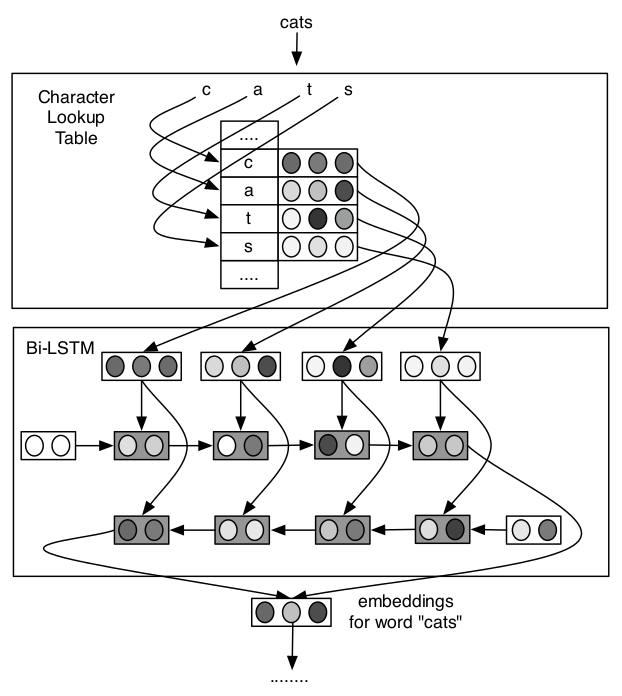
模型使用双向LSTM对character embedding进行处理并将两个方向最终的隐状态向量拼接作为word embedding输出。
Hybrid Word-Character Models
character embedding与word embedding不同在于:word embedding是在巨大语料集上学习好的,然后再用于NLP的各种下游任务,而character embedding是随机初始化的,在学习下游任务目标的同时学习character embedding。考虑到word embedding和character embedding各自都包含了有用的信息,因此Christopher D. Manning等人提出了综合使用word embedding和character embedding的混合模型Achieving Open Vocabulary Neural Machine Translation with Hybrid Word-Character Models,这篇文章发表于ACL2016,模型使用单向LSTM网络,具体结构如下
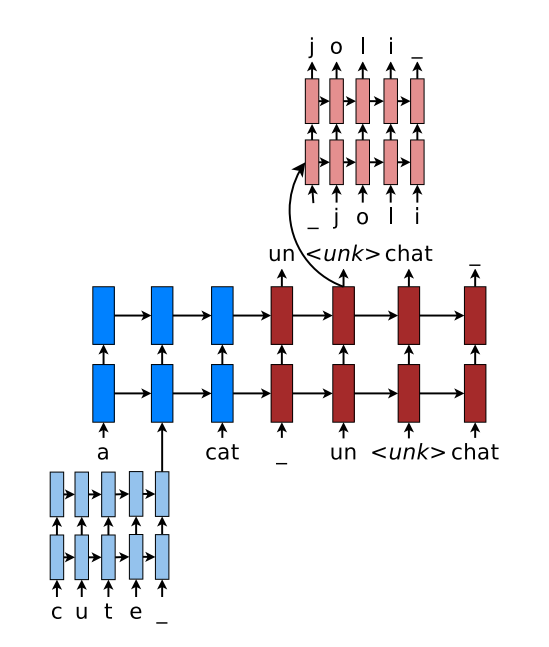
对于输入序列中的OOV word使用双层LSTM处理其对应的char embedding得到的输出作为word embedding,对于输出序列中的\
WordPieces
wordpieces这个名字取得很形象,说白了就是将词划分成片表示,但可不是随便划分。目前的划分方法主要有两种:
- 基于频率计数的方法byte pair encoding(BPE)
- 基于unigram language model的方法
byte pair encoding
Neural Machine Translation of Rare Words with Subword Units,这篇文章发表于ACL2016。文章思路其实很简单,初始化所有的wordpieces为单个字符,就是统计相邻两个wordpieces在所有word中共现频率,然后合并出现频率最高的wordpieces,直到当前词汇表满足设定的大小。注意,合并起来的wordpieces的所有前缀都要包含进词汇表中。下面是BPE算法的python代码

代码一目了然,但正是这么简单的方法却在很多NLP下游任务上取得了很不错的效果,因而得到了广泛的应用,毕竟简单而又好用的谁不喜欢呢!!
unigram language model
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates,这篇文章发表于ACL2018。文章基于输入语料库建立unigram model,使用EM算法迭代,每次保留去除该词后使得语言模型的perpelxity损失最大的前80%的词,迭代计算直到当前词汇表满足设定的大小。
Google’s SentencePiece
SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing,这篇文章发表于EMNLP2018,在发表这篇文章之前,google也发表了一篇基于unigram language model的建立wordpieces词汇表的文章Japanese and Korean voice search,这篇文章发表于IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)2012。但SentencePiece这篇文章可谓集大成者,Google在这篇文章基础上开源了github: SentencePiece Package,它不仅包含常用的character和word embedding,并且实现了前述2种subword segmentation algorithms即BPE和unigram language model,Google真乃良心啊,这就为后面所有NLPer的工作提供了提供了一个统一的输入预处理工具。并且该工具还可以保存构建wordpieces的model,便于论文实验结果的再现(reproducibility,因为很多NLP模型对输入极其敏感,输入稍有偏差将导致结果迥然不同)。SentencePiece Package上手使用非常简单,下面给出代码:
1 | import sentencepiece as spm |
Train方法中的参数说明如下
--input: one-sentence-per-line raw corpus file. No need to run tokenizer, normalizer or preprocessor. By default, SentencePiece normalizes the input with Unicode NFKC, . You can pass a comma-separated list of files.--model_prefix: output model name prefix..modeland.vocabare generated.--vocab_size: vocabulary size, e.g., 8000, 16000, or 32000--character_coverage: amount of characters covered by the model, good defaults are:0.9995for languages with rich character set like Japanse or Chinese and1.0for other languages with small character set.--model_type: model type. Choose fromunigram(default),bpe,char, orword. The input sentence must be pretokenized when usingwordtype.
执行上面代码后会在当前目录下生成subword.vocab和subword.model两个文件,下面给出加载模型进行编码解码的代码示例
1 | import sentencepiece as spm |
fastText embedding
wordpieces以很巧妙的思想解决了OOV的问题,后面出现了大量的使用wordpieces作为embedding的工作。这里不得不提一下fastText: Enriching Word Vectors with Subword Information,这篇文章是facebook ai团队发表于TACL2017,这篇文章使用和word2vector一样的学习embedding的方法skip-gram,但是它是学习word的subword n-grams(文章中n设为3~6,就是word的所有连续的3~6grams) embedding,这样其它任务使用词向量出现OOV现象即可使用该词n-grams的subword embeddig累加来合成。那么如何训练subword n-grams 的embedding呢?就skip-gram进行讨论,假设center word为$w_t$,window word为$w_c$,则围绕$w_t$的loss为
其中,$\mathcal{N}{t,c}$ is a set of negative examples sampled from the vocabulary. 我们用$\mathcal{G}w \subset {1,…,G}$ 表示出现在w中的n-grams集合(3~6 grams in paper),$z{g}$表示$w$每个n-gram的embedding,$w$的向量表示为$z_g$的和,因此可得$s(w,c)$
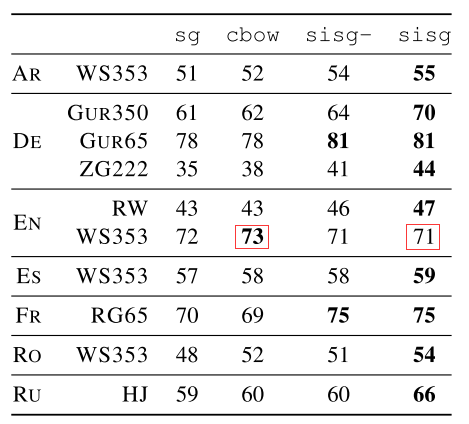
该方法异常高效,train cost非常低,不同以往的word embedding学习需要海量的文本数据进行学习,fastText只需要word2vec方法的5%甚至1%的数据即可在许多任务上达到一致的效果。下图是word2vec的cbow方法以及fastText的skip-gram方法使用不同大小数据集训练后在word similarity任务上spearman rank表现对比
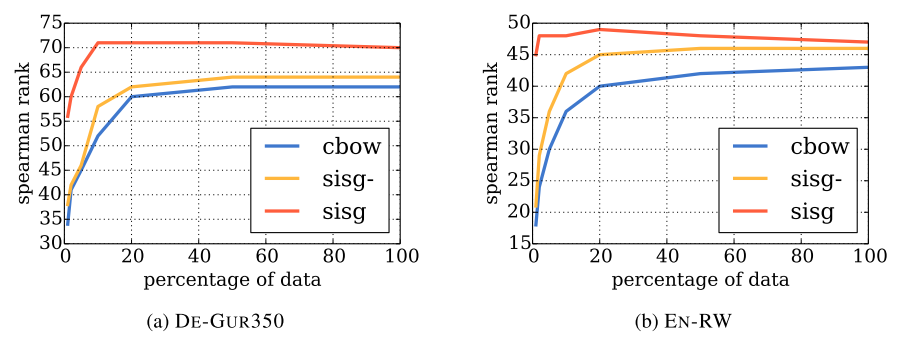
其中,sisg-是fastText使用null vector表示OOV word,而sisg是fastText使用summing subword n-grams表示OOV word,可以看到sisg使用少量数据之后即可效果基本就饱和了。fastText对于复合词多、词尾变化丰富、多形态词的语言,以及包含大量生僻词的语料库效果更为明显,因为这些很难直接用word embedding直接覆盖,非常适合使用subword n-grams来拼接表示。但是对于常见词使用直接word embedding效果会比subword n-grams embedding效果更好,如下图所示,可以看到在word similarity任务上,fastText在WS353 dataset上表现不如word2vec的cbow,because words in the English WS353 dataset are common words for which good vectors can be obtained without exploiting subword information.
所以前面提到的Hybrid Word-Character Model也正是发现此问题后的进一步优化,能优先使用word embedding的就是用word embedding,否则使用character embedding或者wordpieces embedding。