ELMo(Embeddings from Language Models)是发表在NAACL2018的论文Deep contextualized word representations提出来的模型,属于feature-based预训练语言模型,其后的ULM-fit与其模型基本一致,但在训练和迁移阶段使用了更多的分层适用的概念,属于fine-tuning预训练语言模型。
ELMo模型的简略模型结构图如下
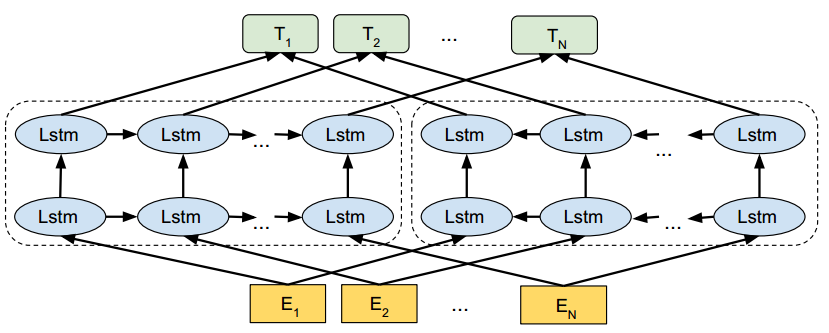
主要分为两大模块:
- token representation
- Multi-BiLSTM
下面分别给出这两个模块的一些细节
token representation
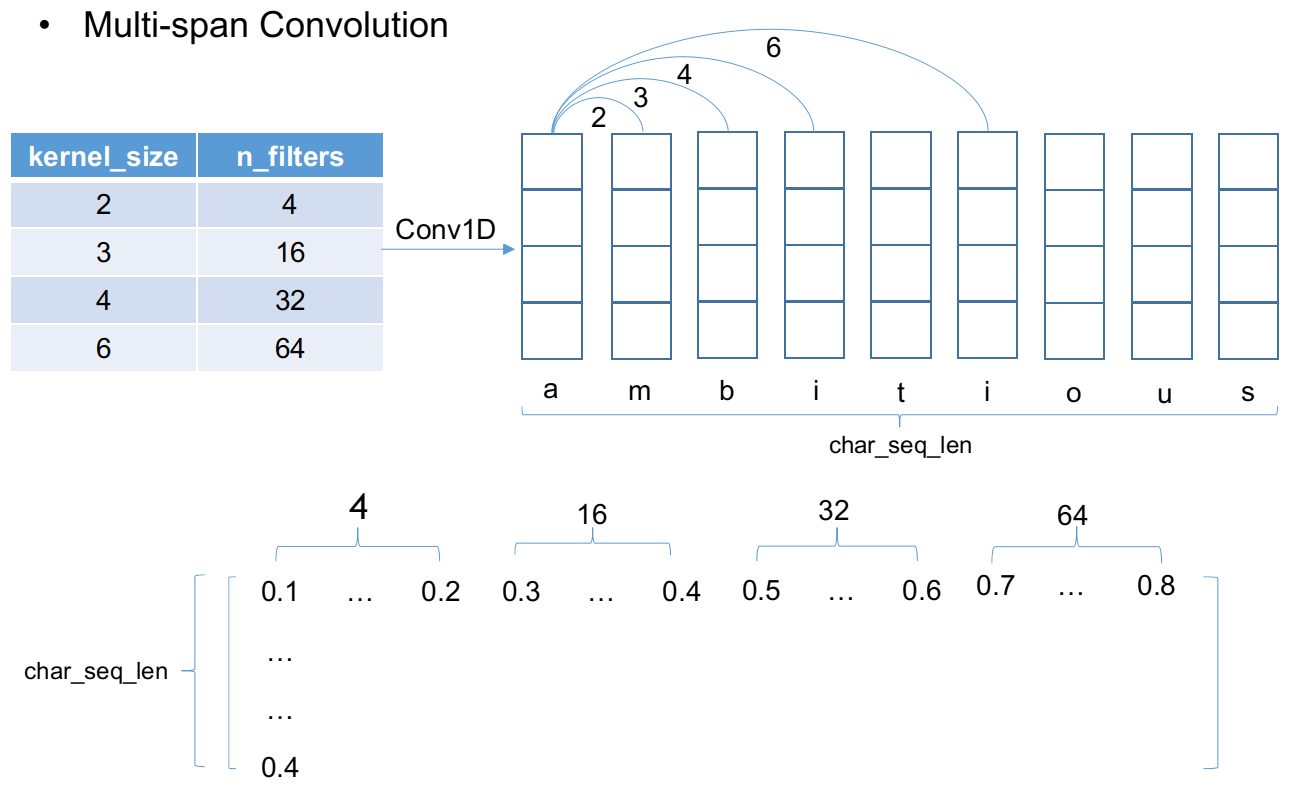
ELMo模型的token representation采用了character embedding,拥有更强大的表示能力,并且使用多个不同跨度的卷积核进行一维卷积,不同kernel卷积得到的不同表示拼接在一起,然后经过两层highway network得到最终的预处理编码表示。下图是一维卷积获取character embedding的具体操作示意图
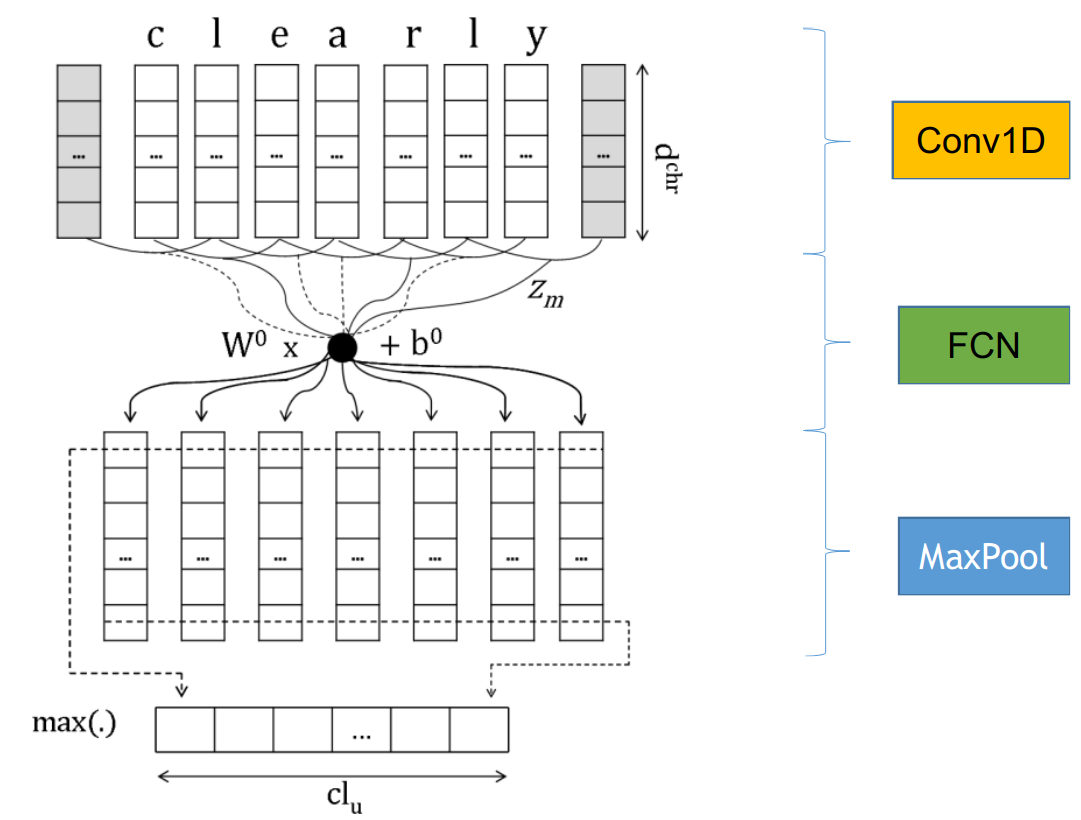
多跨度多kernel的卷积拼接获取character embedding的具体操作示意图如下
将拼接得到的character embedding输入到两层highway network进行处理,highway network其实就是CV领域著名的ResNet中使用的残差单元的原型,highway network模型结构图如下
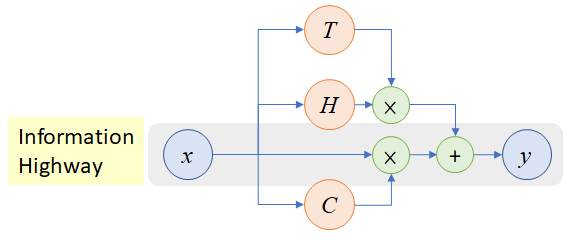
highway network的表达式描述为
特别地,当$C=1-T$
其中$H,T,C$都是非线性转换,$W_H,W_T,W_C$分别为它们对应的参数。
Multi-BiLSTM
下图是LSTM的模型结构试图以及每个control gate的计算式
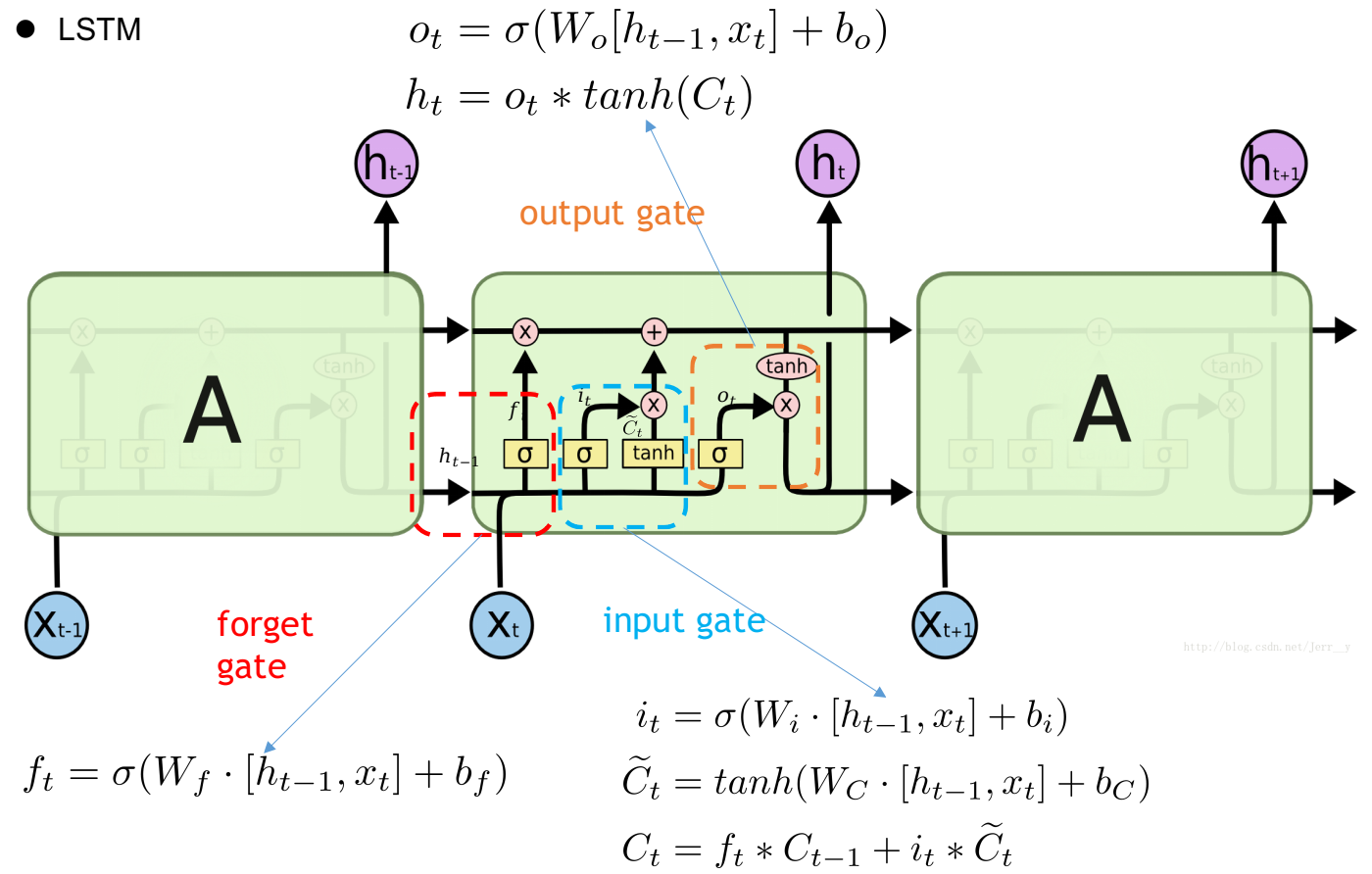
BiLSTM则是使用一个正向一个逆向的LSTM处理sequence得到每个token的hidden state进行拼接作为这个token最终的输出。而Multi-BiLSTM顾名思义就是多层的双向LSTM,将当前这一层BiLSTM的正反向hidden state拼接输出作为紧邻的上一层的输入,最后一层的输出才是token最终的输出。
downstream application
ELMo使用feature-based的方式应用到下游任务,就是将模型输出表示加入(一般是拼接)到任务模型中的某一层中或多层中以增强任务模型对文本的表示能力。具体方式在这里我直接引用原文更好理解:
a L-layer biLM computes a set of 2L + 1 representations
$h{k,0}^{LM}=[x{k}^{LM},x_{k}^{LM}]$ for token representation
$h{k,j}^{LM}=[\overrightarrow{\mathbf{h}}{k, j}^{L M}, \overleftarrow{\mathbf{h}}_{k, j}^{L M}],j \gt 1$ for each biLSTM layer, compute a task specific weighting of all LM layers
$s_{j}^{\text {task}}$are softmax-normalized weights and the scalar parameter $\gamma^{\text {task }}$allows the task model to scale the entire ELMo vector.
下游任务可以根据优化的目标函数对ELMo表示的权重$s_{j}^{\text {task}},\gamma^{\text {task }}$进行学习得到合适的权重。