Lecture 08 Machine Translation, Seq2Seq and Attention
Statistical Machine Translation(SMT)
统计机器翻译(Statistical Machine Translation,SMT)出现并流行于1990s~2010s,1990s以前的MT工作大部分都是基于规则的(rule-based),使用双语词典作为映射,最早可以追溯到1950s。SMT的main idea如下图所示
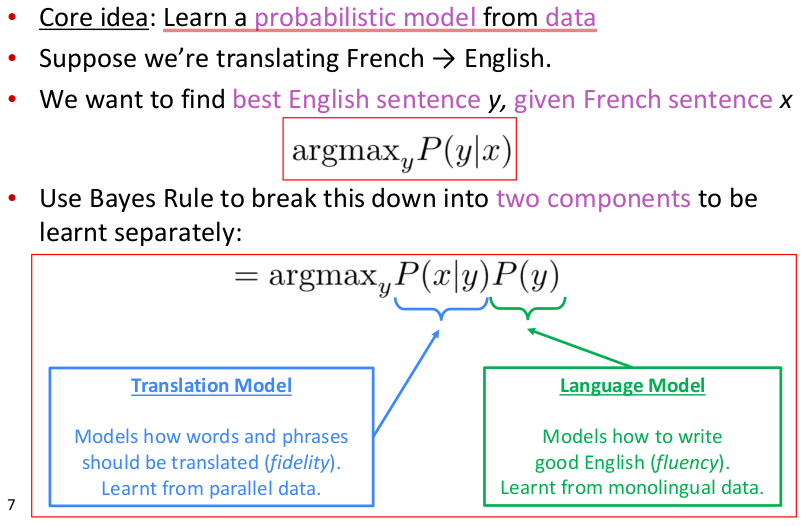
SMT将模型划分为2部分进行学习,左部主要用于确保翻译后的句义保真度,尽可能学习到原句的真实含义。而右部主要用于确保翻译后句子的流畅度。机器翻译还有一个难题就是对齐(alignment),原句和目标语句之间的语法可能差异很大,使得词序排列分布差异很大,要学习原句词与目标句词之间的对齐方式是一件非常棘手的事。定位alignment关系非常复杂,因为alignment有一对多、多对一以及多对多的关系,SMT通过加入一隐变量a用于专门学习alignment,即将$P(x|y)$进一步划分为$P(x,a|y)$,其中a物理含义是原句与目标句之间word-level correspodence.
Nueral Machine Translation(NMT)
seq2seq model
seq2seq model的结构如下图所示
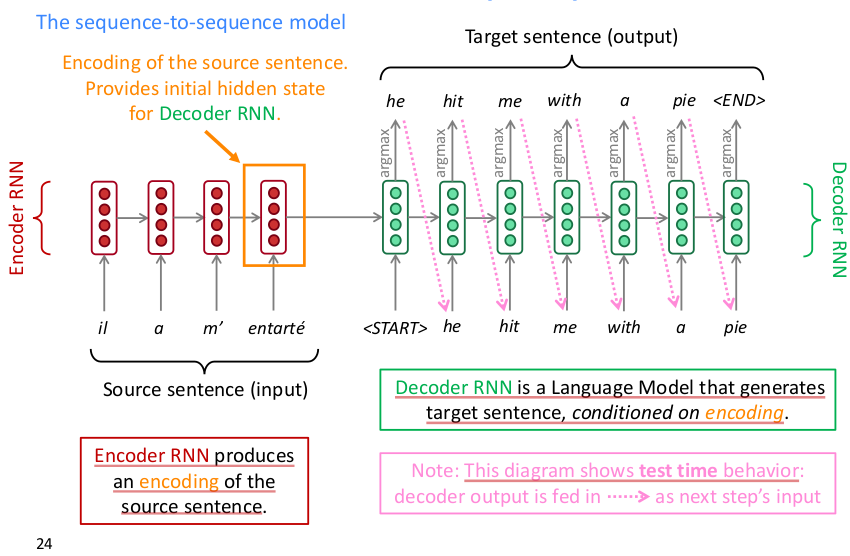
从上图看seq2seq应用于NMT的方式一目了然,这是一个auto-regressive model,通过历史序列信息学习预测当前词,loss为交叉熵。seq2seq无须对输入数据进行预特征提取,直接将原始序列输入即可得到目标序列输出,一个典型的端到端黑箱模型。正由于其简便易用,得到了很多应用,seq2seq model还能应用于

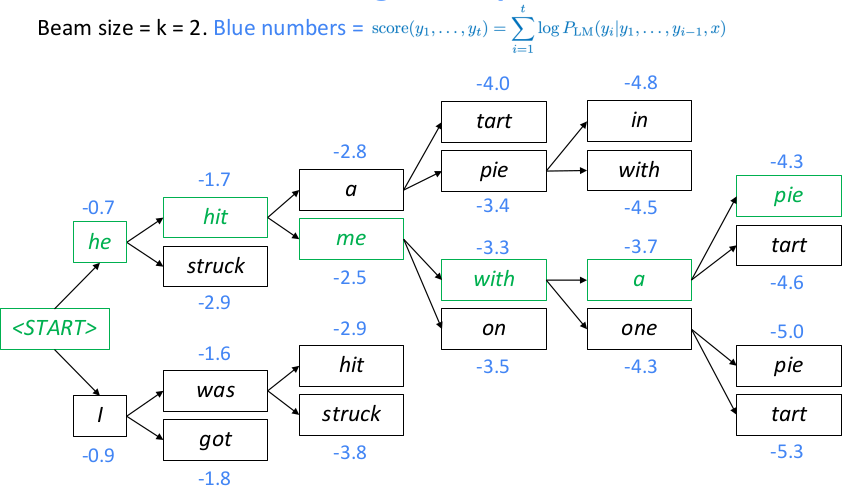
一般beam size设置越大,寻找到的结果更优,但不一定是最优,只有搜索所有路径才可以得到最优解,一直搜索直到预测到结束标记,概率值为language model的log probability的前缀和,因此序列越长log probability的和可能越小,结果要除以对应序列长度来比较候选序列。通常可以设置概率阈值、候选序列个数、预测序列长度限制来作为搜索的终止条件。由于beam search容易使用来自训练集中的常见短语和重复文本,因此Hierarchical Neural Story Generation这篇文章提出使用top-k random sample scheme的方法,简单概括就是先选出LM生成概率最高的k个词,然后从这top-k个词中随机采样一个词作为下一个序列生成词,重复上述步骤直到生成终止词。 MT task的评估一般采用BLEU,可以参考assignment4 handout或者paper bleu,NLTK提供了基于句子和语料库计算bleu score的API,注意计算整个corpus的bleu不是求corpus中每个句子bleu的均值,而是累加每个句子的ngrams统计信息到同一个分子分母中统一计算得来。bleu取值范围[0,1],但是论文中都习惯将bleu乘以100后保留一位小数来表示。
NMT相比SMT的优点如下

NMT缺点在于不可解释的黑箱,难以调试,有结果超乎预料的风险。
Attention Mechanism
seq2seq model简便以用,但是瓶颈也很明显如下图所示
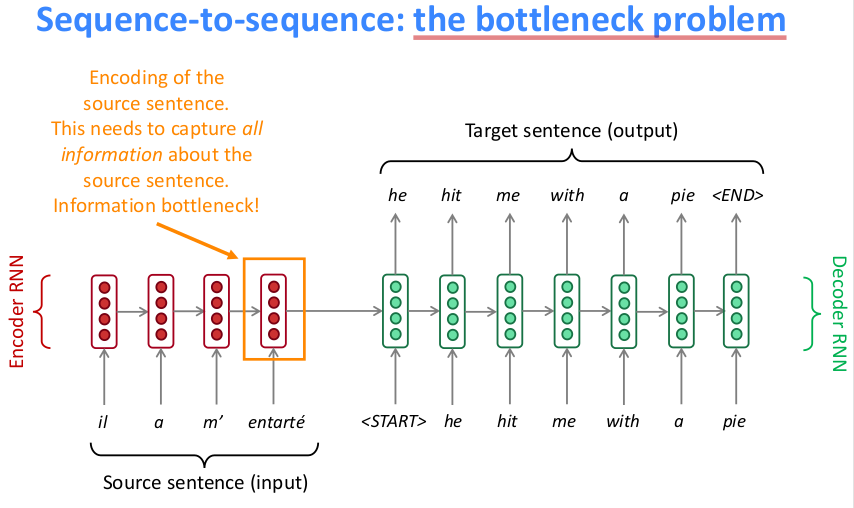
最后一个词输出的hidden state需要囊括句子的所有信息,而LSTM对于长距离问题又无法很好地解决,因此最终的hidden state肯定丢失了很多的信息。为了能很好的提取前面所有词的编码信息,需要引入注意力机制
core idea: on each step of the decoder, use direct connection to the encoder to focus on a particular part of the source sequence
seq2seq引入attention的具体方式如下所示
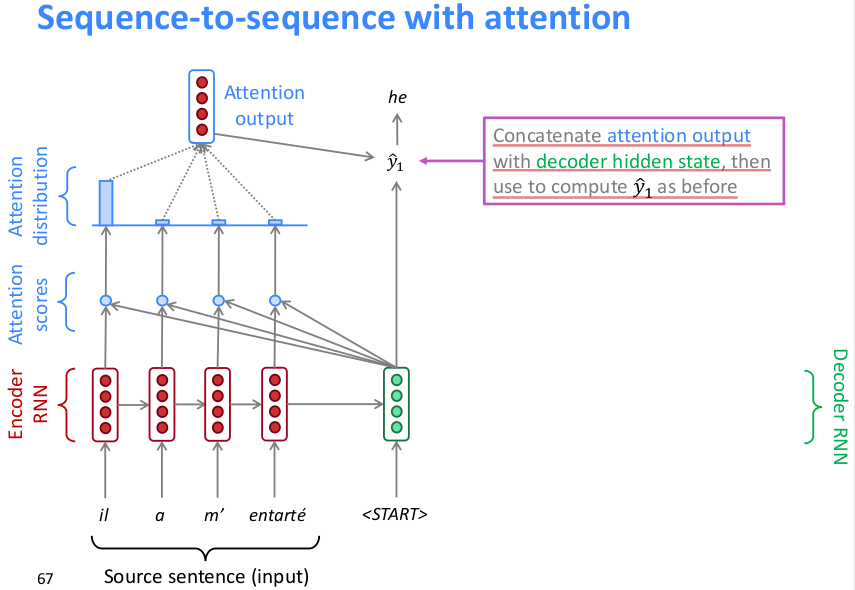
如上,将原句编码后的hidden state向量与原句中每个词的编码向量作点积运算得到每个词的attention score(scalar),然后softmax所有词的attention scores得到attention distribution(上图可以看到attention在下一相关词上分布最多),然后再用attention distribution对词编码向量作加权求和得到attention output,然后concat到decoder的hidden state预测下一个词。下图是下一层的执行方式
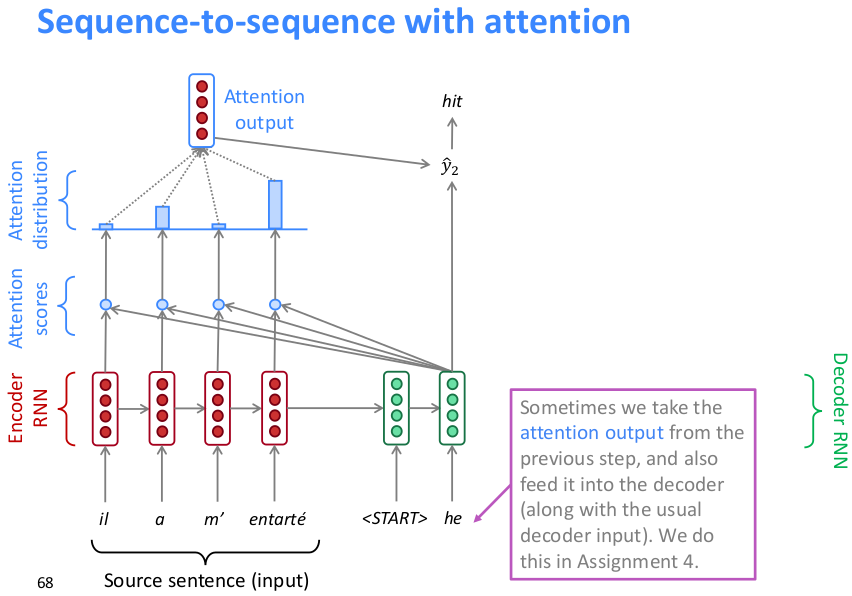
将前一层的attention output和前一层的预测输出词向量concat作为这一层的输入,由于此时hidden state是拼接的要取原句子编码向量那一段输入到attention机制中,得到的attention output同样concat到当前的句子编码中用于预测下一词。
attention正是通过直接与句子中所有word embedding进行点积(direct connection),并将attention distribution用于句子中所有词向量的加权求和从而解决了LSTM无法解决的长距离依赖问题,使得hidden state包含了句子更丰富的信息,从而能更好得预测下一个词。
attention不仅是用于seq2seq model,它有更general的用途如下

attention mechanism有三种常见变体形式如下

